企业的敏感数据类型多样,并且往往分散在不同的业务系统和数据库中。由于历史原因,企业的数据库也大多是孤岛式建设、异构的系统。随着云计算、大数据等新技术的发展,越来越多的企业将数据存储在多个公有云或私有云中,这些数据可能分布在不同的地理位置,或者由不同的服务提供商托管。大量分散的、异构的数据源给敏感数据的发现和识别带来巨大的困难,由于缺乏统一的敏感数据目录清单,企业很难准确地掌握敏感数据的分布和状态。

随着企业数字化业务更新迭代速度的加快,敏感数据的类型、数量、所处的物理位置和逻辑位置,也都在快速变化,如果不能及时掌握这些变化,不能及时了解敏感数据的使用和流动状况,企业就很难建立起一致的敏感数据保护策略,难以有效地管理敏感数据。

面对海量数据库、表、字段和个性化的分类分级模板,人工核验标注准确性需逐项审核字段数据的命名规则、语义内容与关联业务场景, 效率低下且标准易偏移。同时,合规规则与业务场景持续迭代,分类分级策略需频繁调整,人工更新极易滞后或遗漏。 此外,很多情况下数据分类分级工作需要与业务部门协同完成标注准确性核验,协同工具的缺乏也会导致人工工作量巨大,效率低下。
在数据安全治理的场景中,数据分类分级的目的是更加有效地保护敏感数据。如果数据分类分级成果不能与数据保护技术措施无缝衔接,或是需要依赖大量的人力投入来实现管理上的协同,势必会降低数据分类分级成果的价值,增加敏感数据保护和管理的成本。
原点安全一体化数据安全平台 uDSP 内置功能强大的敏感数据发现、识别引擎和分类分级工具,并支持接入本地化部署或公共大语言模型, 帮助企业自动化完成数据资产盘点、数据分类分级等工作,快速构建统一视图的敏感数据目录,并且能够实现敏感数据目录与数据保护技术无缝衔接, 快速落地敏感数据保护技术措施。
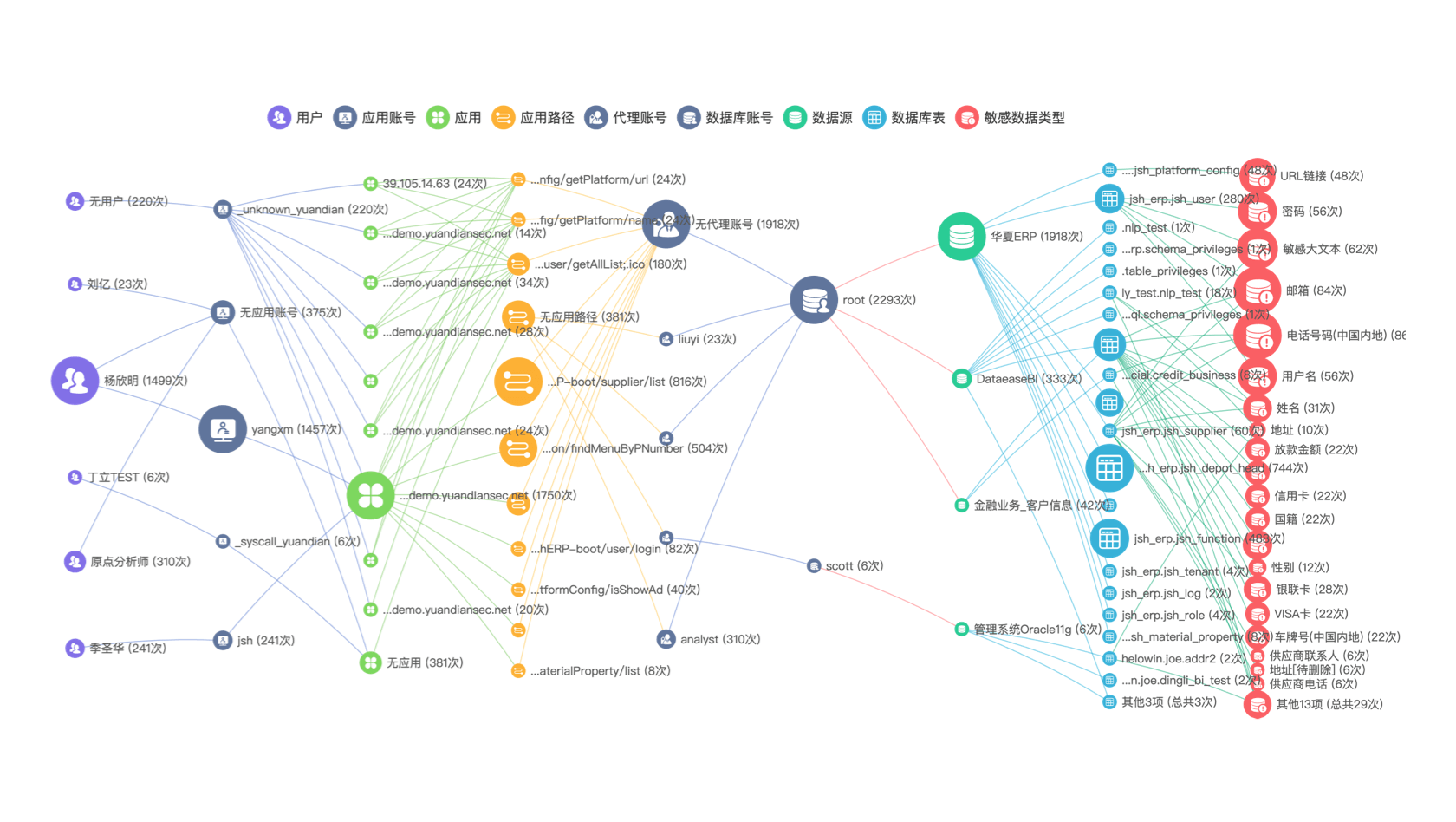
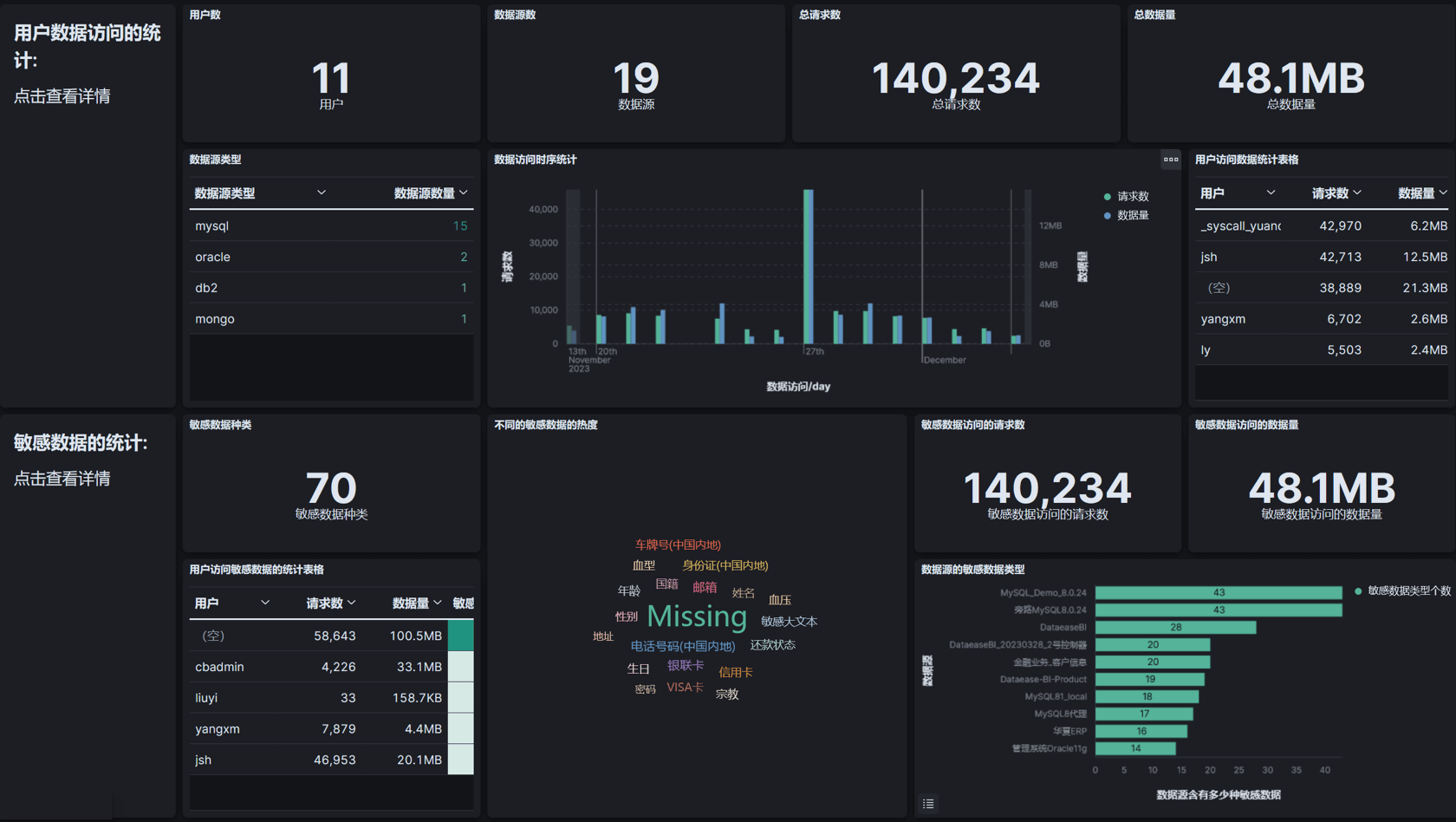
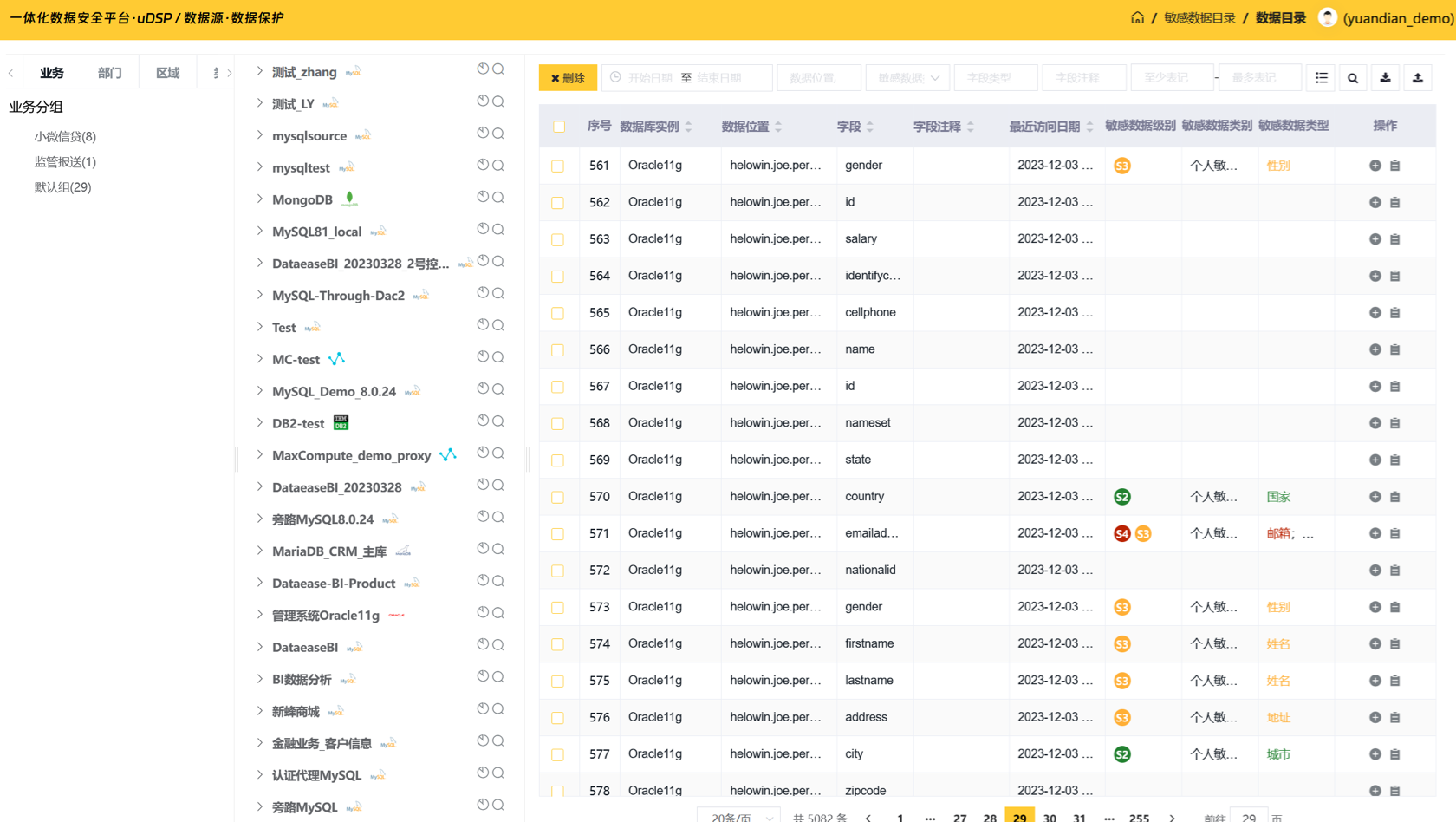
屏蔽分散、异构数据源的差异和复杂性,全面覆盖敏感数据并形成统一的敏感数据目录可视化视图;可自定义的实时敏感数据分布地图,完整掌握敏感数据资产动态,满足监管上报等多样化的管理诉求。
“双模引擎”自动化识别“被动发现+主动扫描”双模式敏感数据自动发现和识别引擎,保证敏感数据目录的完整性及新鲜度,及时发现新增、变化的敏感数据类型,自动标记并更新敏感数据目录。
数据分类分级模板内置敏感数据通用识别规则,支持自定义识别规则和机器学习算法模型;提供多个行业敏感数据分类及分级标准模板,同时支持自定义分类分级模板。
大语言模型辅助分类支持接入本地化部署或者公共大语言模型辅助数据分类标注,极大增强上下文语义理解能力,显著提升自动化处理效率,保障分类分级的准确性和持续优化。
业务人员协同打标数据安全人员下发任务及规则,业务人员登录数据门户协同打标,打通不同业务组之间协作难点,让数据分类分级工作更便捷高效。
无缝衔接保护措施以敏感数据目录为核心,无缝衔接数据安全保护技术措施,针对敏感数据配套差异化的安全策略,提供细粒度、精细化的数据权限管控、数据动态脱敏、数据安全审计、数据风险分析等安全能力。